UE5 性能优化分析实践(UE Insights使用)

UE5 性能优化分析实践(UE Insights使用)
Shadow DrunkUE5性能优化实践初试
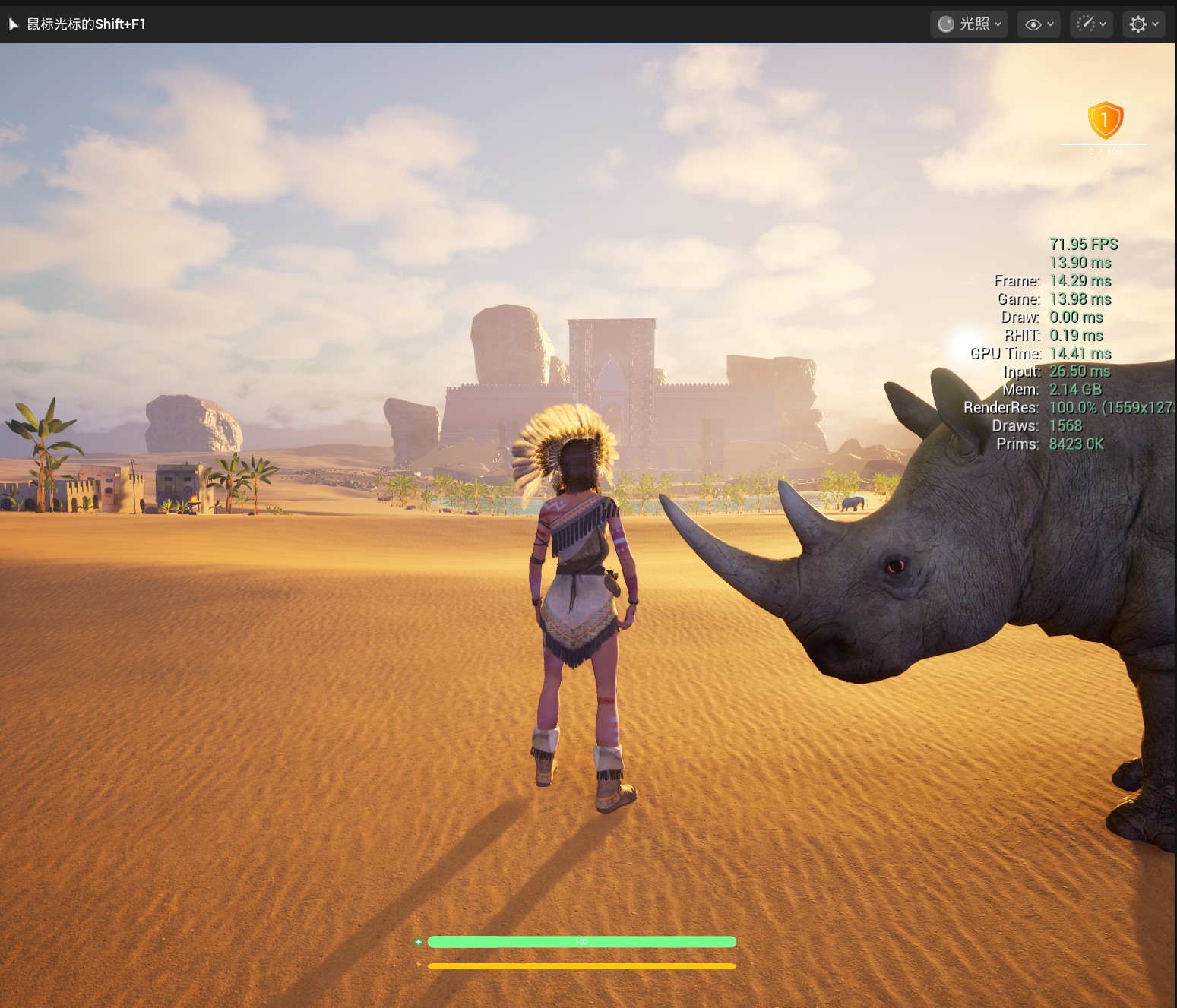
在我个人使用UE5制作完我的第一个3DRPG-Demo制作完成时遇到了比较严重的性能问题,普遍帧率只能稳定在30帧,极端情况下甚至只能有20。于是便有了本篇博文的优化及分析流程。主要使用UE insight进行追踪记录分析。
一.常用分析工具和指令
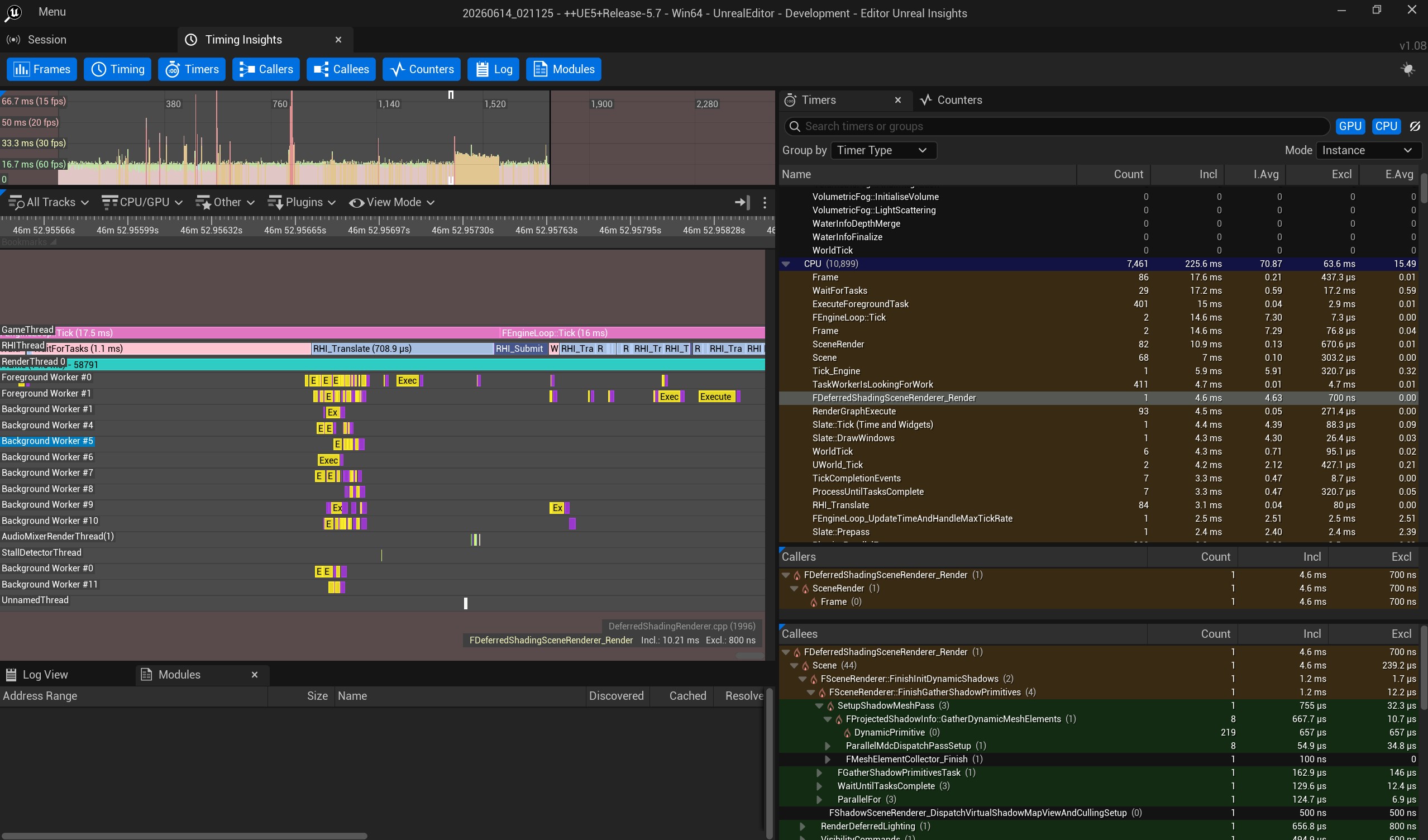
1.UE Insights
面板基础操作和概念
帧面板
- 鼠标左/右拖动: 左右滑动平移帧
- 水平缩放: 鼠标滚轮
- Shift + 鼠标滚轮: 垂直缩放
时间面板
- 鼠标左/右 上下拖动:水平或垂直平移
- Ctrl + 鼠标滚轮:水平滚动
- Shift + 鼠标滚轮:垂直滚动
- 鼠标滚轮:缩放
- 鼠标左键点击时间事件:选择时间事件
- Ctrl + 鼠标左键双击:选择选定时间事件的时间范围
- 鼠标在时间标尺上左右拖动:选择时间范围
- 鼠标左键点击空白处:取消选择
- F:框住上个选择,然后选择框住聚焦时间范围或时间事件
- C:在正常和紧凑模式之间切换,影响时间事件的显示方式
- G:切换图表轨迹可视性,显示游戏和渲染帧
- Y:切换GPU时间轨迹可视性
- U:切换CPU时间轨迹可视性
- 双击事件:即可高亮显示同一类型(定时器)的所有时间事件,并屏蔽所有其他事件,双击空白处取消
Inclusive Time 和Exclusive Time
- Inclusive Time: 是函数调用包含其子函数的时间
- Exclusive Time: 是函数调用本身的时间不包含其子函数调用时间
Callers 和 Callees
- Callers:此函数的调用者信息
- Callees: 此函数调用的函数的信息
2.性能分析视图
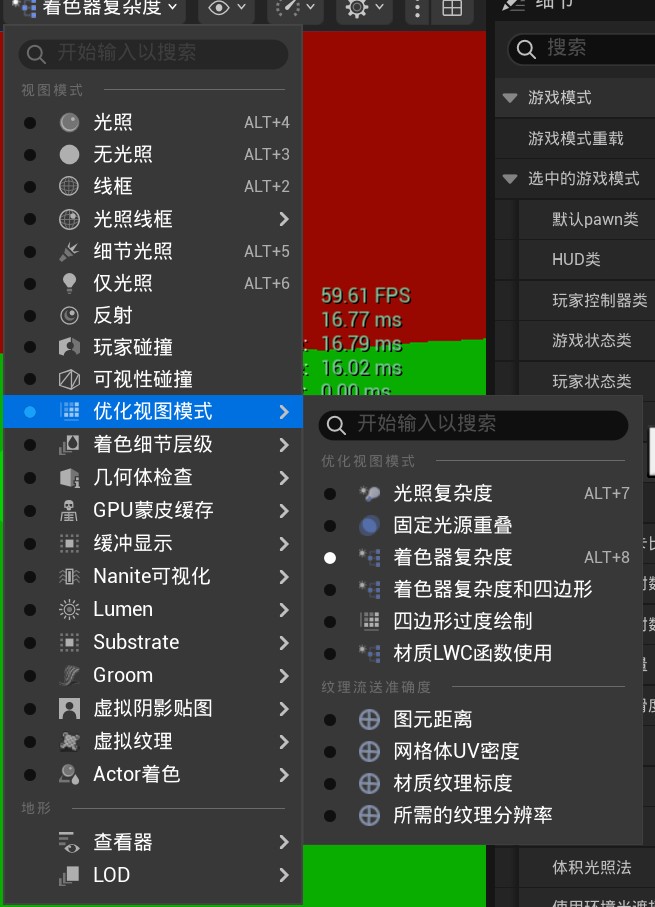
使用性能分析试图可以查看具体场景材质,光照,渲染等复杂度。
3.一些常用指令
t.MaxFPS 60 设置帧率上限
stat FPS 视口显示帧率
stat unit 视口显示线程消耗
stat SceneRendering 更详细的Render消耗,查看 Mesh Draw Call 的数量
r.ScreenPercentage 50 表示将渲染的像素数量减半(也可替换成其他 0-100 之间的数),观察卡顿现象是否明显减缓,以此判断瓶颈是否 Pixel-bound
ShowFlag.DynamicShadows 0 使用该指令可关闭场景内的动态阴影(0表示关闭,1表示开启),可在开启和关闭两种状态间反复切换,查看卡顿情况是否发生明显变化,以此判断 Dynamic Shadow 是否确实造成了巨大开销
二.UE的线程架构含义和工作流
UE 采用了混合多线程模型(专用线程 + 任务图工作线程)
1. 核心专用线程 (The Dedicated Threads)
这是引擎运转的“心脏”,主要负责整个游戏循环的生命周期。
- GameThread (游戏线程): 引擎的主逻辑线程。所有的
Tick()函数都在这里执行。包括处理玩家的输入(比如你的连招输入缓冲逻辑)、物理引擎的状态同步、生成或销毁 Actor、执行蓝图节点、以及运行 AI 行为树(Behavior Trees)。它是唯一可以直接安全访问UObject和绝大多数游戏性 C++ 类的线程。 - RenderThread (渲染线程): 负责收集来自 GameThread 的绘制信息。它不直接和 GPU 沟通,而是执行视锥体剔除 (Culling)、可见性计算、排序,并生成与平台无关的渲染命令。
- RHIThread (渲染硬件接口线程): 负责将 RenderThread 生成的通用渲染命令,翻译成特定图形 API(如 DirectX 12, Vulkan, Metal)的底层指令,并提交给 GPU 执行。它的存在极大地减轻了渲染线程的负担。
2. 任务图系统工作线程 (Task Graph Workers)
UE 会根据当前设备的 CPU 核心数自动生成一组 Worker 线程,用于处理并发的 C++ 任务。
- Foreground Worker (前台工作线程): 处理高优先级的任务。通常是那些 GameThread 或 RenderThread 正在等待结果的关键任务(比如并行的动画结算、某些关键的物理计算)。
- Background Worker (后台工作线程): 处理耗时较长、无需立刻返回结果的异步任务。比如关卡流式加载 (Level Streaming)、异步资源的 IO 处理、着色器编译,或者你在 C++ 中丢进后台的复杂寻路算法(如 A* 或 JPS)。
3. 其他系统线程
- AudioMixerRenderThread: 现代虚幻音频引擎 (Audio Mixer) 的专属线程。它在后台异步处理音频的混合、DSP 特效(如混响、衰减)以及解码,确保复杂的游戏音效不会阻塞主游戏循环。
- StallDetectorThread: 卡顿检测线程。它在后台“监视”其他核心线程,如果发现 GameThread 或 RenderThread 长时间未响应(发生死锁或死循环),它会触发崩溃报告并记录调用栈,是 Debug 的好帮手。
- UnnamedThread: 通常是底层操作系统(OS)生成的线程,或是某些未接入 UE 线程命名规范的第三方 SDK(如某些网络底层库)创建的独立线程。
- NetworkThread: 如果项目涉及多人联机,处理 Socket 接收/发送和网络数据包序列化。
- IOStore / File I/O Threads: 专门用于处理现代游戏庞大的磁盘读取请求,特别是在使用打包的 .pak 或 IOStore 格式时。
- PhysicsThread (Chaos): 在 UE5 的 Chaos 物理引擎中,如果开启了异步物理计算,会有一个专门的物理线程(或利用 Task Graph)来步进物理模拟。
- 第三方中间件线程: 比如集成了 Wwise/FMOD 音频引擎,或者 Havok 物理,它们会维护自己的底层线程池。
4.管线工作流
UE 采用了多帧延迟管线 (Multi-Frame Pipelining) 来最大化 CPU 和 GPU 的并行效率。
它们的工作流程可以总结为经典的 “N / N-1 / N-2” 同步模型:
阶段 1:逻辑处理 (GameThread - Frame $N$)
游戏线程计算当前的第 $N$ 帧。你的角色移动了位置、AI 决定了攻击动作。GameThread 计算完毕后,会通过
ENQUEUE_RENDER_COMMAND宏,将需要渲染的数据(位置、材质参数等)打包推送到一个线程安全的队列中。阶段 2:渲染准备 (RenderThread - Frame $N-1$)
在 GameThread 计算第 $N$ 帧的同时,RenderThread 正在处理 GameThread 上一帧(第 $N-1$ 帧)发来的数据。它生成绘制命令列表 (Draw Calls)。
阶段 3:硬件提交 (RHIThread & GPU - Frame $N-2$)
同样在同一时刻,RHIThread 正在将 RenderThread 第 $N-2$ 帧处理好的指令翻译给 GPU,GPU 开始真正的光栅化或光线追踪计算。
同步与阻塞 (Wait States):
为了防止三个阶段脱节(比如游戏逻辑跑得太快,渲染跟不上),UE 会在每帧末尾进行同步。如果 RenderThread 积压了超过一帧未处理的命令,GameThread 就会被迫休眠等待(呈现为 GameThread Stall);反之亦然。
5.个管线主要消耗问题
Game Thread
Game Thread 造成的开销,基本可以归因于 C++ 和蓝图的逻辑处理,瓶颈常见于Tick 和代价昂贵的逻辑实现(Expensive Functionality)
Tick
大量物体同时 Tick 会严重影响 Game Thread 的耗时
stat game:显示 Tick 的耗时情况
dumpticks:可将所有正在 tick 的 actor 打印到 log 中
复杂逻辑
需要借助 Unreal Insights 等工具对游戏逻辑中开销较大的代码进行定位,后续将详细说明它们的使用方法
Draw Thread (Rendering Thread)
Draw Thread 的主要开销来源于 Visibility Culling 和 Draw Call
Visibility Culling
Visibility Culling 会基于深度缓存(Depth Buffer) 信息,剔除位于相机的视锥体(Frustum)之外的物体和被遮挡住(Occluded)的物体,当游戏世界中可见的物体过多,剔除所需的计算量也将变大,导致耗时过长
stat initviews:显示 Visibility Culling 的耗时情况,同时还能显示当前场景中可见的 Static Mesh 的数量(Visible Static Mesh Elements)
三.Render Passes
以下是 UE5 默认渲染管线(以 Deferred Rendering + Nanite + Lumen 为主)中核心 Render Passes 的执行顺序及其具体功能:
1. 深度预处理与剔除 (PrePass / Early Z & Culling)
在真正画出颜色之前,引擎需要先决定“哪些东西能被玩家看到”。
- Nanite Culling & Rasterization: UE5 的核心特色。大量使用 Compute Shader(计算着色器)在 GPU 端进行极致的实例和微多边形剔除。它将可见的 Nanite 几何体光栅化,并输出到专门的高精度深度缓冲区 (VisBuffer)。
- Depth Prepass (Early Z): 针对非 Nanite 的传统网格。仅计算并写入网格的深度信息 (Z-Buffer)。这能极大减少后续复杂材质着色时的 Overdraw(过度绘制),避免为看不见的像素浪费算力。
2. 基础通道 (Base Pass - GBuffer Generation)
这是传统延迟渲染的第一步“重头戏”。
- 功能: 渲染场景中所有不透明 (Opaque) 和遮罩 (Masked) 材质。它不计算光照,而是提取材质的物理属性,并将它们并行写入多个渲染目标 (Multiple Render Targets, MRTs),组成 GBuffer。
- 数据包含: Base Color (底色/反射率)、Normal (法线)、Roughness (粗糙度)、Metallic (金属度)、Specular (高光) 以及 Depth (深度)。
- 工程视角: 这一步非常消耗显存带宽 (Memory Bandwidth)。材质图 (Material Graph) 中指令越复杂,Base Pass 的开销就越大。
3. 自定义深度与模板 (Custom Depth / Stencil Pass)
这是一个可选通道,开发者可以手动标记某些 Mesh 参与此 Pass。
- 功能: 将特定物体的深度或模板 ID 写入一个独立的 Buffer 中。
- 应用场景: 在 ARPG 或 MOBA 游戏中极为常见。例如实现 Boss 受击时的轮廓闪烁、玩家角色被墙体遮挡时的透视描边 (X-Ray),或者是特定区域的技能遮罩。
4. 阴影与光照准备 (Shadows & Lighting Setup)
在计算最终光照前,引擎需要准备好阴影数据和全局光照的缓存。
- Virtual Shadow Maps (VSM): UE5 默认的阴影方案。它将阴影数据分割成虚拟的页 (Pages) 并按需缓存,极大提升了超高精度网格下的阴影渲染效率。
- Lumen Scene Update: 更新 Lumen 的表面缓存 (Surface Cache) 和场景体素化信息。为接下来的光线追踪和间接光计算做数据准备。
5. 延迟光照通道 (Deferred Lighting Pass)
利用前面生成的 GBuffer 数据,结合场景中的光源,计算最终的像素颜色。
- Direct Lighting (直接光照): 计算平行光、点光源、聚光灯等对像素的直接照射效果。
- Lumen Global Illumination (全局光照): 替代了以往的烘焙光照图或 SSGI。利用屏幕空间追踪 (Screen Tracing) 和硬件/软件光线追踪,计算光线的多次反弹(漫反射间接光)。
- Lumen Reflections (反射): 替代了传统的 SSR 和反射捕获探头,提供精准的动态表面反射。
6. 大气与体积效果 (Sky, Atmosphere & Fog)
- 功能: 评估参与介质 (Participating Media)。计算体积雾 (Volumetric Fog) 和天空大气 (Sky Atmosphere)。
- 应用场景: 光线穿过树林或 Boss 战场景中弥漫的烟尘时产生的“丁达尔效应 (God Rays)”,就是在这个 Pass 中结合光照数据计算得出的。
7. 半透明通道 (Translucency / Forward Pass)
半透明物体无法像不透明物体那样简单地写入 GBuffer(因为它们需要和背后的颜色进行混合),所以必须延后处理。
- 功能: 按照从后向前 (Back-to-Front) 的严格顺序,使用前向渲染逻辑绘制半透明材质。
- 应用场景: 水面、玻璃,以及战斗系统中最核心的粒子特效 (VFX) 和技能拖尾。
- 工程视角: 在复杂的战斗场景中,多个全屏级的技能特效叠加会导致灾难性的透明度 Overdraw,这是游戏客户端性能优化的重灾区。
8. 后期处理 (Post Processing)
图像此时还是 HDR(高动态范围)的线性数据。Post Process Pass 会在二维图像空间对其进行各种“电影级”修饰。
- TSR (Temporal Super Resolution) / TAA: 进行时间序上的抗锯齿处理,并将低分辨率的渲染结果高质量地拉伸至目标分辨率。
- Tone Mapping (色调映射): 将 HDR 颜色压缩映射到显示器能正常显示的 LDR 范围内(通常使用 ACES 曲线)。
- 其他特效: Bloom (泛光)、Depth of Field (景深)、Motion Blur (动态模糊)、Color Grading (色彩校正) 都在此依次执行。
9. UI / HUD 通道 (Slate Pass)
- 功能: 渲染玩家的血条、小地图、技能图标等用户界面。
- 特点: 它是管线的最后一步,直接覆盖在最终画面上,不受景深、泛光等场景后期处理的影响。
四.具体分析

首先通过UE Insight的捕获可以确定是GPU瓶颈,Game 线程里主要是等待任务和死等。发现BasePass的时间占用过高,检查使用的网格体资源。最终发现Nanite的开启不全,很多场景中使用植被画刷大量绘制的小石子没有开启Nanite,导致需要渲染的网格体过于复杂。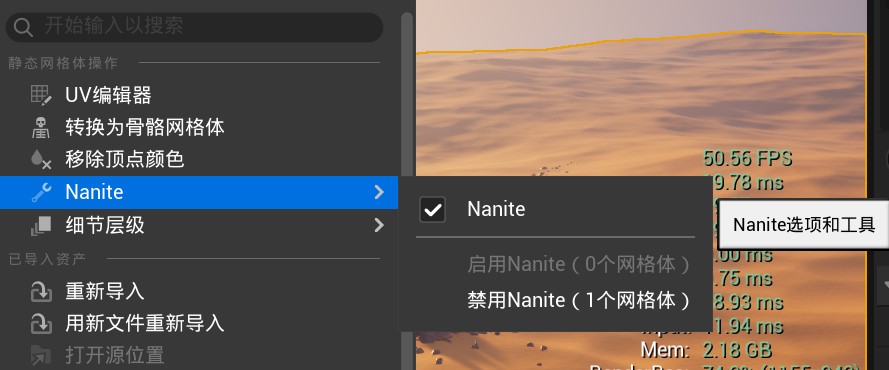
全面启用 Nanite:
检查场景中的静态网格体,确保绝大部分(尤其是环境物件)都开启了 Nanite。这能将几何体的渲染压力降到极低。 //效果j基本最低帧率从20直接变到了40,实际主要是为场景中比较多的小石块启用了这个功能,减少了BasePass(基础通道)和 PrePass(深度预通道 / Early Z),降低了渲染多边形的压力。
在其中一个需要计算大量遮挡剔除的场景体现比较明显,这些复杂而多的地上的小石子,虽然这些小石子最终不会被渲染在画面中,但其进行遮挡剔除没启用Nanite时面数过多,计算压力大。
开启了之后BassPass的时间消耗显著降低。
配置Cull Distance Volume
考虑到之前的小石子的剔除消耗,为场景配置了Cull Distance Volume,它是一个空间体积,你把它放入关卡并放大包裹住你的场景。在这个体积范围内的所有静态网格体(Static Mesh),都会根据自身的包围球直径(Bounding Sphere Diameter),自动匹配你设定好的裁剪距离。

| 序号 (Index) | Size (物体包围球直径) | Distance (消隐距离) | 适用物体举例 |
|---|---|---|---|
| 0 | 0.0 |
1000.0 (10米) |
极小的碎石、地面散落的小纸片、微小杂物 |
| 1 | 50.0 |
2500.0 (25米) |
水杯、武器道具、小草丛、散落的砖块 |
| 2 | 120.0 |
5000.0 (50米) |
木箱、椅子、较大的灌木、瓦罐 |
| 3 | 300.0 |
10000.0 (100米) |
房屋门窗、大型桌子、NPC摊位 |
| 4 | 600.0 |
20000.0 (200米) |
较小的树木、单体小建筑、围墙段 |
| 5 | 700.0 | 0 |
使用了如上的Cull Distances 的数组。这个的效果并不明显。
注意Cull Distance Volume 对「植被画刷(Foliage Tool)」绘制出来的任何东西都完全无效。普通方式拖进场景的物体叫做 Static Mesh Actor(静态网格体 Actor),每一个都是独立的个体,引擎可以单独计算它们与摄像机的距离并决定是否剔除。而用植被画刷刷出来的几千、几万个小石子,在引擎底层使用的是 HISM(层级实例化静态网格体) 技术。 为了极大节省 Draw Call,GPU 会把这几万个小石子当成“同一个物体”来批量渲染。既然它们在底层被打包在了一起,Cull Distance Volume 就无法把它们拆开来单独按距离隐藏了。如果你的石子开启了 Nanite: 那么其实你完全不需要(也不应该)手动去设置这些剔除距离。Nanite 是像素级别的全自动动态多边形缩放技术。远处的石子会被 Nanite 自动压缩成仅仅只有几个像素甚至几个顶点的开销,渲染成本几乎为零。
重新分析性能发现Game线程里出现了一个较大时间消耗的DrawWindows。
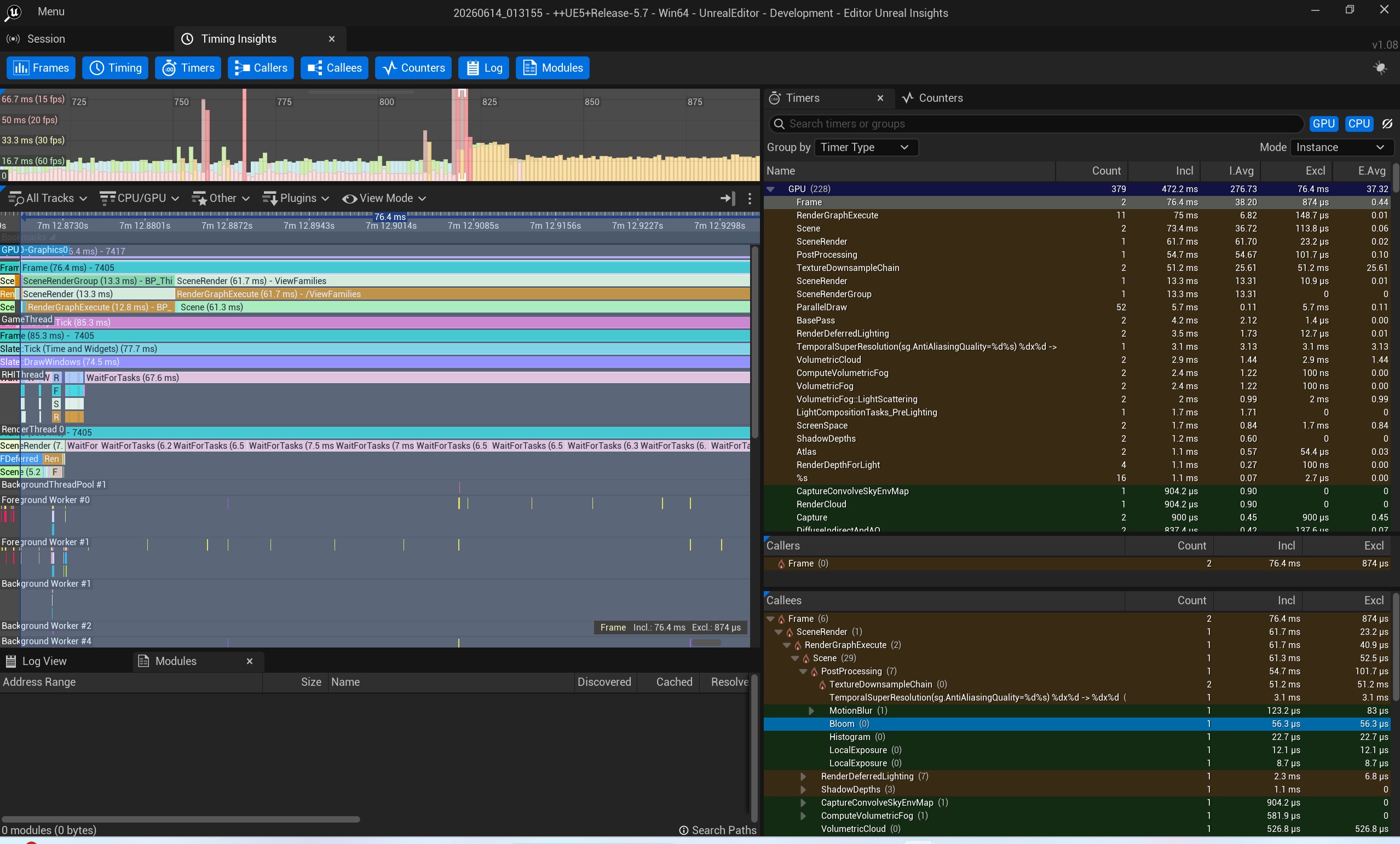
检查我当时打开的ui界面,是一个装备界面,其可能带来性能消耗的主要是背景的模糊,和中间的场景捕获组件,通过配置开关组件,基本可以确定是因为场景捕获组件带来了较大的性能消耗。
下面是开启了场景捕获组件的Render线程一帧的消耗分布

下面是关闭了场景捕获组件的Render线程一帧的消耗分布

UMG 中的 Background Blur(背景模糊组件)
这是最常见的新手陷阱。当你打开背包、暂停菜单或者技能树时,如果你希望背后的游戏 3D 画面变得模糊,通常会用一个 Background Blur 控件铺满屏幕。
- 底层逻辑: 为了实现这个模糊,引擎必须抓取当前屏幕的全分辨率画面,然后对其进行多次降采样(Downsample)生成多级 Mipmap,最后再混合。
- 致命点: 如果你的屏幕分辨率很高(比如 2K 或 4K),或者
Blur Strength(模糊强度)设置得很大,这个降采样过程会让 GPU 瞬间瘫痪,消耗几十甚至上百毫秒。
高频率、高分辨率的 SceneCapture2D(2D场景捕获)
如果你在 UI 里做了一个实时小地图,或者一个3D角色的实时预览,你大概率会用到 SceneCapture2D 组件将画面渲染到一张 Render Target(渲染目标)纹理上,再放到 UI 里显示。
- 致命点: 如果这个 Render Target 分辨率极高(比如 1024x1024),且
Capture Every Frame(每帧捕获)保持开启状态,同时它还触发了 Mipmap 生成或抗锯齿,就会疯狂榨干性能。
针对 UI 背景模糊:
- 定位 Widget: 回想一下截取这一帧时,游戏里弹出了什么 UI?(主菜单?对话框?背包?)
- 替换或降低强度: 打开对应的 UMG 蓝图,找到
Background Blur。如果不是非要不可,直接删掉,用一个半透明的纯黑/深灰 Image 垫在底层代替。这在商业手游中是非常标准的妥协做法。 - 限制模糊开销: 如果一定要保留,去项目设置里检查 UI 的分辨率缩放,并将
Background Blur的强度限制在合理范围内。
针对 SceneCapture2D(小地图/角色预览):
- 降低分辨率: Render Target 的分辨率尽可能给小,比如小地图 256x256 就足够了,UI 上根本看不出区别。
- 关闭每帧捕获: 取消勾选
Capture Every Frame。只有在玩家移动或者环境发生变化时,才通过蓝图或 C++ 手动调用Capture Scene节点进行更新。 - 限制捕获内容: 将
Capture Source改为Final Color (LDR),并在Show Only Actors列表中只添加必须渲染的物体(排除掉复杂的天空球、后处理体积和不需要的远景)。
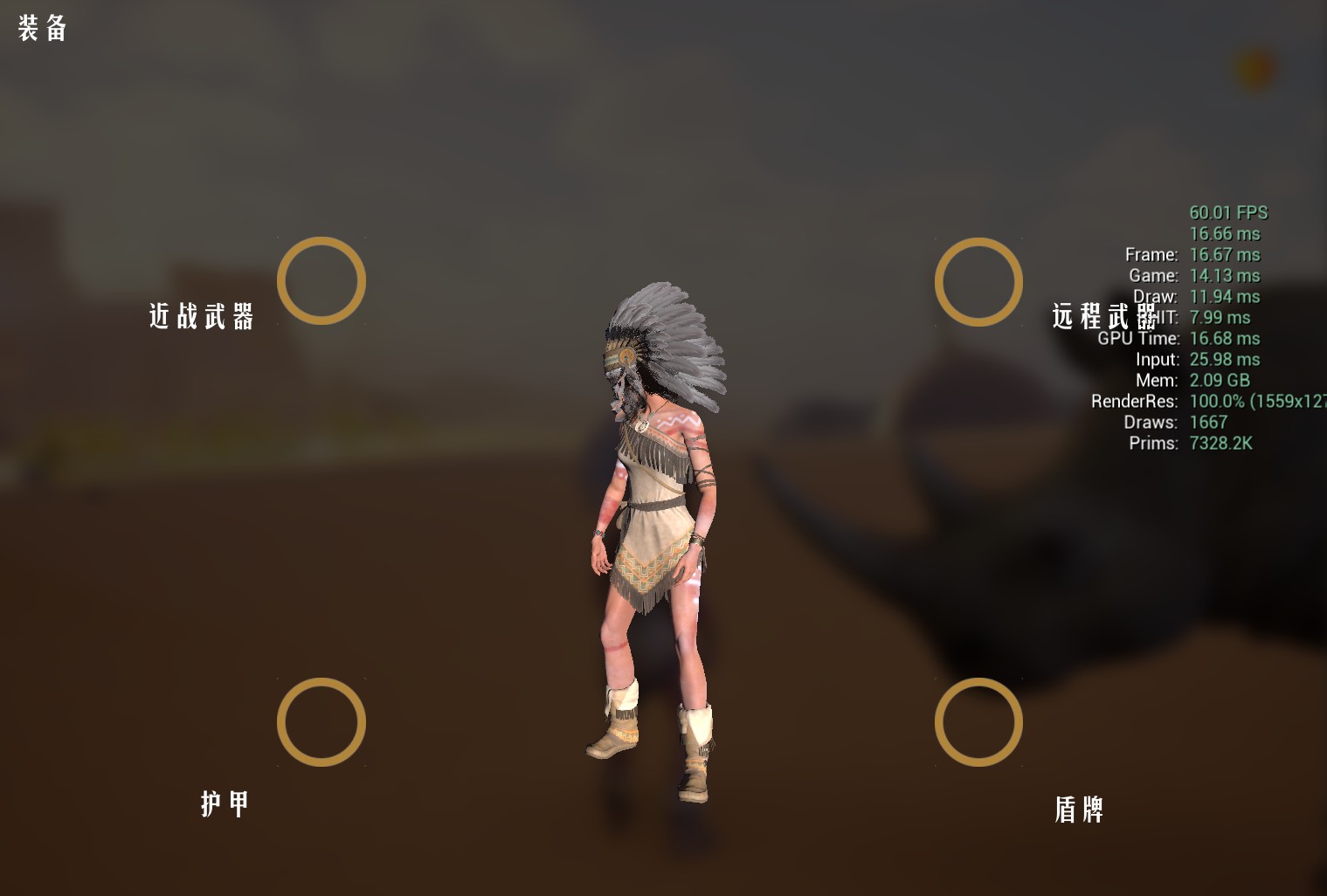
但SceneCapture却在UE Insights里完全没有找到消耗,这是因为 SceneCapture2D 在引擎底层的运作方式,不是执行某一个特定的“高消耗函数”,而是完整地克隆了一遍渲染管线。
简单来说,当你在场景里放了一个场景捕获组件,并开启了“每帧捕获(Capture Every Frame)”,你实际上是对 GPU 下达了这样的指令: “嘿,GPU,把整个游戏世界给主摄像机渲染一遍。等一下,还没完,现在切换到另一个摄像机的位置,把所有的光照、阴影、模型、甚至后期处理,全部再做一遍,然后画到那张 Render Target (RT) 贴图上。”
因此,它的耗时在 Unreal Insights(尤其是 GPU 轨道)中,是被“打散”并伪装成正常的渲染流程的。 如果你仔细看抓帧数据,开启每帧捕获时,你的 GPU 轨道上大概率会出现两次巨大的 SceneRender(或者 FDeferredShadingSceneRenderer_Render)调用块。那凭空多出来的一整个渲染周期,就是你的 SceneCapture2D 干的好事。在 Timers 面板里,它会把你的 BasePass、ShadowDepths、PostProcessing 的总时间无声无息地翻倍或增加。
对于一个只是用来拍“主角 2D 形象”的摄像机来说,如果采用默认设置,它做了太多不必要的计算:
- 黑洞 A:后处理与抗锯齿(Capture Source 带来的) 如果你的
Capture Source设置成了默认的Final Color (LDR) in RGB,为了拍这一张 UI 头像,引擎不仅算光照,还会在这张小图上跑一遍 TSR 抗锯齿、泛光(Bloom)、运动模糊、色调映射(Tonemapper)。这就是为什么你上一帧的后处理时间那么长的罪魁祸首! - 黑洞 B:像素填充率(Render Target 分辨率) 如果你给这个捕获组件绑定了一张 1024x1024 甚至 2K 的 Render Target。即使它在 UI 上只显示鸡蛋那么大,GPU 每帧也要实打实地渲染 100 多万个像素。
- 黑洞 C:背景与不需要的物件 默认情况下,捕获组件会拍下它视野里的所有东西。主角身后的山脉、天空球、远处的怪物,哪怕被主角挡住了,也会进入它的视锥体剔除计算和 BasePass 渲染。
- 黑洞 D:动态阴影 它会为主角(甚至背景)重新计算一遍级联阴影(CSM)或虚拟阴影贴图(VSM)
如上面的分析重新设置了场景捕获组件。

最终效果帧率可以稳定在编辑器中60帧以上